
0.引言
随着信息技术和网络技术的不断发展,互联网给现代人们获取信息带来极大的便利,成为人们工作生活中非常重要的组成部分。信息无障碍即万维网对任何人士(包括残障人士)都是可访问、可用的,残障人士能感觉、理解和操纵Web,与Web
互动。如何借助先进的技术,消除数字鸿沟,为残疾人提供有效的辅助手段,使他们能和健全人一样无障碍地获取网上信息,得到世界各国政府和组织越来越多的重视。
1.信息无障碍网站存在的问题
很多部分实现了信息无障碍的网站,用户每次访问时,网站语音都得从头到尾的播报网站内容,对于该用户曾经访问过本网站中部分页面内容期刊网,系统不能自动过滤掉这些已经阅读的内容,或者跳过这些已阅读信息,而是依然按照布局顺序重复播报。这对于阅读障碍的用户来说非常浪费时间和精力。避免重复浏览或者播报网站信息,将用户曾经阅读过的内容过滤掉,将没有阅读过的最新的感兴趣的网页内容优先播报给阅读障碍用户,提供智能化、个性化信息服务,是信息无障碍网站设计应该重视的问题。
2.
web日志挖掘
web日志文件是在web服务器上每隔一定的时间产生的记录文件,其内容包括访问用户的IP地址,访问时间、访问的页面、页面的大小、浏览器类型、响应状态等等。web日志挖掘是对用户访问Web时服务器方留下的访问记录进行挖掘,得到用户的访问模式和访问兴趣。通过对Web站点的日志记录进行预处理,将日志数据组织成传统的数据挖掘方法能够处理的事务数据形式,然后利用传统的数据挖掘方法进行处理。
web日志预处理过程:
(1)数据收集
从服务器端数据、客户端数据、代理服务器端进行。
(2)数据净化
删除Web日志文件中不是由用户请求,而是由浏览器自动“请求”产生的访问记录。具体包括图片和音频文件、样式文件和脚本文件、不是GET的HTTP方法、弹出式广告的记录等。
(4)会话识别
用户在规定时间内对服务器的一次有效访问,通过其连续请求的页面,可以获得其在网站中的访问行为和浏览兴趣,有4种识别会话的模型:页面类型模型(page type
model),参引长度模型(reference length model),最大前向参引模型(maximal forwordreference
model)和时间窗口模型(time window
model)。最常采用的是时间窗口模型,以用户访问时间作为划分会话的分界,一般间隔时间取30min。
(5)路径补充
用户有时浏览的页面,是从本地缓存和代理服务器中调用的,不会向Web服务器发送请求,也就不会记录日志,而这些请求可能对后续挖掘的实施有重要作用期刊网,缺少这些页面记录可能会使挖掘结果不是很准确。为了能更精确的挖掘用户的行为模式,有必要把这些缺失的路径补充上去即路径补充。如果当前请求的页与用户上一次请求的页之间没有超文本链接,那么用户很可能使用了浏览器上的“BACK"按钮调用缓存在本机中的页面。如果用户的历史访问记录有多个页面都包含与当前请求页的链接,则将请求时间最接近的Web页的页面作为当前请求的来源。
3.基于web日志挖掘的网站设计
3.1网站设计架构
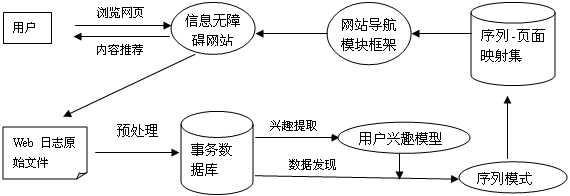
网站为每位存在访问障碍的用户建立网站访问记录数据库,用户访问网站页面,产生web日志文件,通过对web站点日志文件进行数据净化、用户识别、会话识别,将有用数据存入事务数据库,对该用户访问过的页面进行相应标记,再对事务数据库进行传统的数据挖掘,分析出该用户比较感兴趣的信息类型,为该用户对网站所有类型信息构造优先显示页面类型序列表和对每类信息未访问页面、已访问页面分别构造优先序列表,当该用户再次访问网站时利用离线分析所得的优先序列表和网站文件映射数据库将网页链接按照用户兴趣高低动态填充到网站导航框架,这样用户最感兴趣类型的网页链接总是弄够最先看到、听到,从而达到优先访问的目的。
网站设计框架如下图:
图1 信息无障碍网站设计框架
3.2
网站导航
网站导航是根据信息无障碍网站结构布局设计标准所设计的网站通用布局框架,除了包括信息无障碍要求的导航砖,通用切换等功能,还将页面设计成由几个通用的布局框架模块组成,每个框架模块将显示网站上某一种类型的网页信息链接,具体网页链接内容则根据序列表先后顺序动态填充。网站所包含的信息类型可以有很多,但在网站导航中只列出用户最感兴趣的几种类型的网页链接,随着用户兴趣的改变,其他类型的网页链接将动态的填充到相应级别的框架模块中。
3.3
兴趣提取
根据用户浏览的历史访问记录(内容信息和行为信息)、访问时间和访问频率等来分析计算用户兴趣度,用户的兴趣一般集中于某一个主题或者多个主题期刊网,系统在通过聚类进行分析将用户浏览的历史页面集自动地分成n个聚簇(n是聚类中聚类中心的数目),每一聚簇的页面集体现了用户的某类兴趣,构造形成用户的兴趣类。再利用用户的隐式信息学习提取用户兴趣集,建立树状的用户兴趣模型。
3.4
序列模式
序列模式挖掘是对关联规则挖掘的进一步推广,它挖掘出序列数据库中项集之间的时序关联规则。关联规则强调的是两个项之间的关联,序列模式则加强调两者之间的先后次序。这里我们将挖掘出两种序列表:类型序列表和页面序列表。类型序列表是通过对历史访问记录进行挖掘统计出来的网站每种类型信息访问优先等级,是一组有序项集对应表;页面序列表则是以类型挖掘权值和更新时间2个指标得出的页面访问有序集对应表。可以采用基于Apfiori算法的改进算法进行挖掘得到上述两种序列表。
3.5
序列-页面映射
根据挖掘得到的序列模式对网站的静态页面文件进行一一映射,按照兴趣高低和文件序列先后动态的填充如网站导航模块框架中。
4.结束语
本文所提出对web日志文件挖掘提取用户的兴趣类和访问类型和页面优先序列,重构站点页面之间的链接关系,动态显示网页信息的设计框架,以适应有障碍用户的访问兴趣习惯为主要目标,在一定程度上可以避免反复无用的页面浏览和语音播报所造成的对存在访问障碍用户产生的困扰和时间精力的浪费,提高了访问效率,为消除信息鸿沟,真正做到信息人人共享发挥积极的作用。
更多网站建设资料:
Microsoft SQL Server Management Studio 如何导入导出数据
国内社交网站创新研究及网站盈利模式
如何去建立一个好的网站
传统文化网页设计编排重点
电子商务网站建设规划

















 举报不良网站
举报不良网站 高新企业证书编号:GR201644000568
高新企业证书编号:GR201644000568